
Foreword
Today, I’d like to tell you about a proof-of-concept that I’ve just recently implemented in my work. But first, I’d like to tell you how I came to be interested in the subject I’m about to talk about.
I’ve always loved SQL. This language, both simple and elegant, allows you to perform queries within a database as if you were speaking to it directly.
When I was at school, it was perhaps the first time I felt like I was speaking another language in computing. A database will always give you the information you want, as long as you know how to ask for it.
I then became a developer, and I remembered that if I had learned to communicate with a database, it was above all to apply it within my own programs. Including SQL queries in source code, that is.
Like any student, I experienced the joy of writing SELECT * and INSERT INTO in strings concatenated to values I passed in forms, and the wonder of seeing my database data displayed in my web pages.
Like many students, I put my first websites online to show them off to everyone.
Then, like everyone else who’d done the same thing as me, I discovered the joy of getting my database pwned with SQL injections.
What, it’s wrong to write SQL concatenated strings?
I then discovered how to do query preparation.
We all ran into the same problems:
- It’s tedious
- It’s easy to make mistakes
- The fear of letting an injection slip through is always present
- You have to map your objects carefully
For this last point, I speak of “object” in the general case and philosophical sense of the term, although I’m about to illustrate the problem with the Go language, which is not object-oriented.
I wasn’t the only one to notice the need to map structures/classes to database tables. It was these people who created ORMs (Object-Relational Mapping), enabling us to meet this need.
The advantages of ORMs are immense:
- Direct manipulation of objects
- Totally abstracts the SQL layer, no need to write SQL at all
- Greatly facilitates serialization / deserialization
- Simplified CRUD operations
- Simplified relationship management
- Compatibility between several databases (PostgreSQL, MySQL, etc.)
There are also unavoidable disadvantages:
- Loss of performance
- More limited control
- Debugging sometimes more complicated
- Learning of a DSL
While these disadvantages exist, the advantages are far too obvious to ignore. The ORM principle is widely adopted in just about every programming language.
I used to love SQL, but now I have to face facts: writing SQL in this day and age is obsolete. Nobody does it anymore. Or so I thought.
I’ve been talking to my databases via ORMs for years, and I’ve come to terms with it. But I must confess I’m nostalgic for the days when I spoke the language of my databases.
Recently at work, we’ve been confronted with a number of problems linked to the lack of control that ORMs sometimes entail, particularly when we need to change the database schema.
That’s when a colleague came to introduce us to a technology I hadn’t heard of before: sqlc.
sqlc and ORMs
sqlc is a tool that automatically generates code from manually written SQL queries.
It was created to combine the security and performance of raw SQL with the ease of use of an ORM, while avoiding the processing overload and loss of control that ORMs can introduce.
Initially written in Go for the Go language, sqlc now supports several other languages.
Here, we’ll talk about it mainly in Go. To place sqlc within the current ecosystem, we’ll use the GORM ORM for comparison (though other popular alternatives like Ent also exist).
Let’s take a very simple database schema:
|
|
At first glance, it’s a bit of a step backwards: we’re back to using prepared queries written directly in our source code.
In the case of ORMs, SQL is totally invisible.
Adding a row to a database literally takes a line of code:
|
|
However, as mentioned above, we want to free ourselves from the limitations of ORMs. If manipulating databases with an ORM is easy with trivial examples, what about when we want to execute complex queries?
It’s not necessarily impossible, but we sometimes have to make concessions (splitting up queries to delegate some of the calculations to the programming language, creating views, etc.).
Finally, aren’t there other ways of dealing with the disadvantages of manually prepared queries?
sqlc takes the problem the other way round: no dependencies in the code, but a local tool that generates code compatible with the standard library.
Note that code generation to other libraries is also possible, but here it’s the fact of having no dependencies on the standard library that interests us.
The result:
- SQL code is written again
- 100% standard library-compatible code ready for use
But before writing any SQL, sqlc needs to know a few things: which database engine you’re using, where to find your queries and your schema, and where to output the generated code. All of this is defined in a configuration file, sqlc.yaml (or sqlc.json, if you prefer), placed at the root of your project.
Here’s the one I used:
|
|
It’s pretty straightforward: I tell sqlc that I’m using PostgreSQL, that my SQL queries are in sqlc/database/*.sql, that the database schema is defined by the migration scripts in sqlc/database/migrations, and that the generated Go code should go into the sqlc/database package.
With this in place, a simple sqlc generate command is all it takes to generate the code.
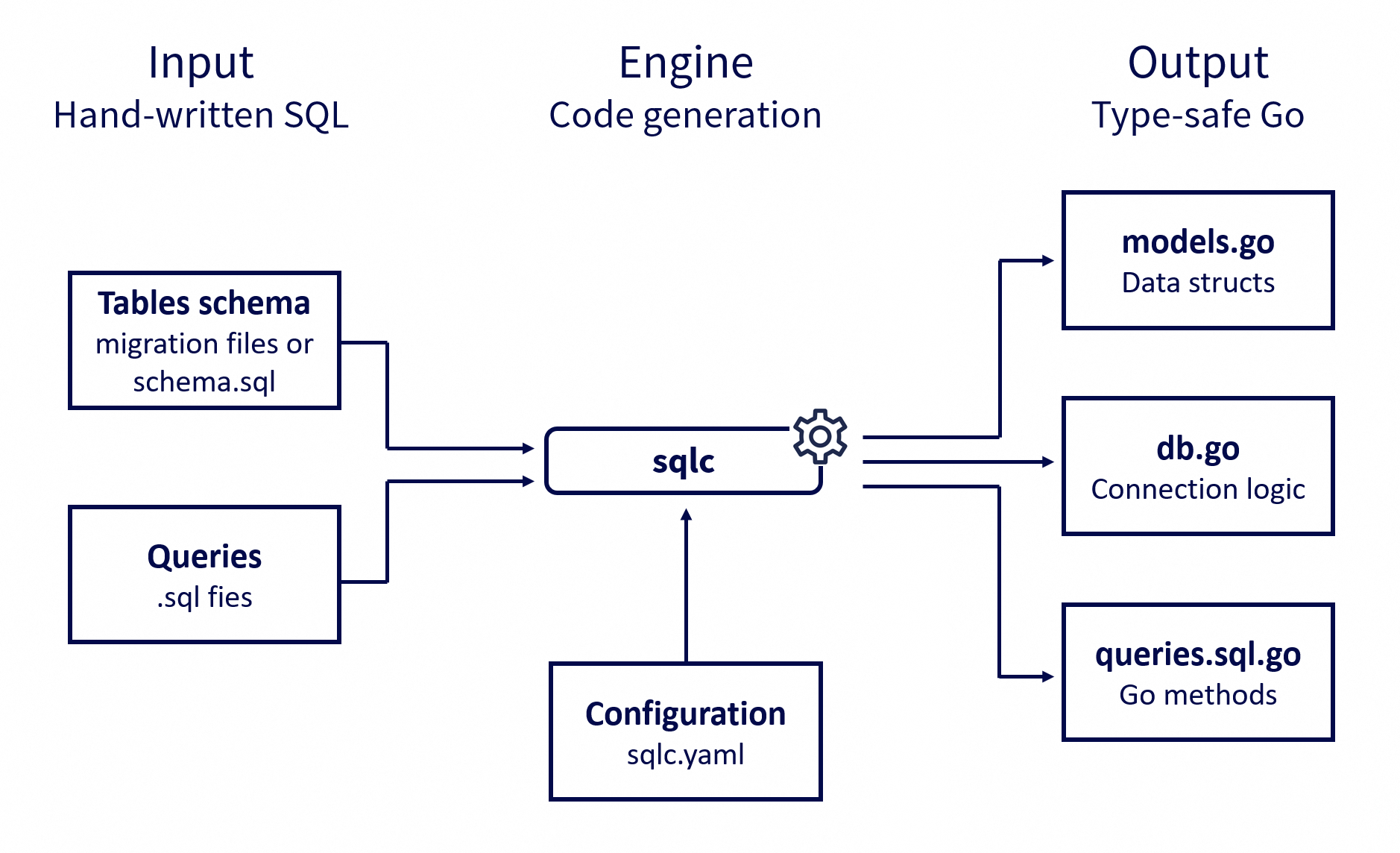
Now, let’s get into the SQL.
Just add a comment above the queries to specify the desired function name, followed by an annotation indicating the return type: :one for a single result, :many for a list, :exec for execution with no return, :execresult to get the sql.Result, :execrows for the number of affected rows, or :execlastid for the last inserted ID.
author.sql
|
|
author.sql.go (generated file)
|
|
It’s another way of looking at the problem: no more writing boilerplate, no more fear of potential injections due to human error.
In short, the benefits are very similar to those provided by ORMs, but with full control over queries and no runtime overhead. Indeed, unlike some ORMs that heavily rely on reflection at runtime, the code generated by sqlc is executed exactly as is, with no loss of performance.
You can find a more complete example on the sqlc Playground.
Writing SQL is cool.
You’ll notice that the SELECT * has been transformed into SELECT id, email, bio in the generated code.
Indeed, sqlc replaces SELECT * with an explicit list of columns to guarantee the stability of the generated code, optimize performance and avoid errors linked to schema changes.
You’ll then notice that the comparison between the use of functions provided by an ORM and those generated by sqlc is quite similar.
GORM
|
|
sqlc
|
|
In the case of sqlc, we use a structure of type *Queries, which is an encapsulation of DBTX, an interface that defines a contract for executing SQL queries. Both are generated by sqlc.
We’re free to use them as we wish. For my part, I’ve chosen to make the generated functions internal (hence the fact that they start with a lowercase), in order to encapsulate them in exported functions of the same name that I define as *Queries methods.
And that’s all there is to it! Just as easy to use as before, but with many advantages.
Besides, there are other advantages. I’d like to draw attention to two of them that I really appreciate.
Firstly, the templates are also generated by SQL scripts.
Model generation
Here are the Go models generated by my SQL scripts:
|
|
Now that you’re beginning to understand the concept of sqlc, these models have obviously been generated by SQL scripts.
So here’s an SQL script that would allow the generation of these templates:
|
|
It works, but in the corporate world, database tables are rarely static. They evolve. That’s why you’ll usually find migration scripts.
This is where it gets interesting: if sqlc is able to generate our models via SQL, it can then do so via migration scripts directly.
Here are the scripts I actually used to obtain the same result:
v0001.sql
|
|
v0002.sql
|
|
v0003.sql
|
|
At my work, database management is handled by a dedicated team. They have their own Git repositories, and we do PRs with them to evolve our schemas.
Thanks to sqlc, we can now add these repos directly via Git submodules to ensure that sqlc fetches the scripts from these repos to generate our models.
Before, we had to replicate the data models within our code, with the human errors that this could entail.
This method provides a real and reliable link between the code of our microservices and that of the database migrations.
The database team thus becomes the real source of truth.
As an example, I’ve reproduced this proof-of-concept at home: https://github.com/sebferrer/poc-sqlc ;
and stored my migration scripts in a dedicated repo: https://github.com/sebferrer/poc-sqlc-db
Transactions
One thing worth knowing: sqlc does not generate transactions automatically. If you want to execute several queries within the same transaction, you have to handle it yourself.
But it’s not that complicated, because sqlc provides a handy mechanism for that. The generated code includes a WithTx method on the *Queries structure, which lets you associate your queries with an existing transaction:
|
|
The idea is simple: you start a transaction via the standard library, then create a new *Queries instance tied to that transaction using WithTx. From that point, all queries executed on this instance will be part of the same transaction.
Here’s a concrete example: imagine we want to create an author and immediately assign a book to them, all within the same transaction.
|
|
If either operation fails, the defer tx.Rollback() takes care of rolling back the whole transaction. If everything goes well, tx.Commit() commits the transaction.
Some subtleties
Parameter structures
sqlc generates Go structures to encapsulate SQL query parameters, but only when there is more than one parameter. If the SQL query has only one parameter, sqlc does not use a structure and passes the corresponding value directly to the function.
In the example above, a structure has been generated to pass the necessary parameters so that it can be passed to the function that was also generated:
|
|
It would have been the same for the SELECT query if it had needed more than a single parameter.
On the other hand, if only one parameter is needed for the query, sqlc won’t bother creating a structure for nothing:
|
|
|
|
Return structure
How does sqlc manage the return type to return the selected data? It’s pretty straightforward.
If the SELECT includes all table columns, like a SELECT *, it will directly use the type generated before to define the data model.
|
|
|
|
Otherwise, it generates an intermediate structure, leaving us free to choose how to handle it.
|
|
|
|
Embedding with sqlc.embed
When writing queries that involve JOINs, the generated result struct usually contains a flattened list of all selected columns. This can become cumbersome to work with.
For instance, the following query fetches books along with their authors:
|
|
sqlc would generate a flat struct like this:
|
|
With sqlc.embed, you can tell sqlc to reuse existing model structs instead:
|
|
The generated struct will then be much cleaner:
|
|
This keeps the generated code well-organized and avoids having to manually extract each field from a flat row.
Named parameters with sqlc.arg
sqlc tries to generate meaningful names for positional parameters, but sometimes it doesn’t have enough context. For example:
|
|
|
|
Not very readable. With sqlc.arg, you can explicitly name the parameters:
|
|
|
|
If the syntax feels too verbose, you can also use the shortcut @:
|
|
Note: the
@shortcut is not supported in MySQL.
Nullable parameters with sqlc.narg
sqlc infers the nullability of parameters, and usually it does what you’d expect. However, if you want to force a parameter to be nullable when it wouldn’t have been inferred as such (because the column is NOT NULL), sqlc provides sqlc.narg (nullable arg), which lets you do exactly that.
This is particularly useful for partial updates, where you want a field to remain unchanged if no new value is provided.
Here’s an example that allows updating an author’s email, bio, or both:
|
|
|
|
Here, without sqlc.narg, the email parameter would have been generated as a string (non-nullable) since the column is NOT NULL. By using sqlc.narg, we force it to be sql.NullString, so we can pass NULL to mean “don’t change this field.”
The flip side: dynamic queries
It’s not all rosy, however. Where an ORM like GORM shines with its ability to build dynamic queries (adding a Where() only if a variable is defined, for example), sqlc shows its limits. Since everything is frozen at compile time, managing a search bar with ten optional filters quickly becomes a headache.
We might be tempted to use a trick with some “heavy” SQL like WHERE (column = $1 OR $1 IS NULL), but let’s be honest: this is rarely a viable solution on serious projects. It’s verbose, hard to maintain, and often a disaster for performance as soon as the table grows in size.
In this kind of scenario, you have to stay pragmatic: the best option, in my opinion, is to forgo sqlc for these specific cases and use a Query Builder (like Squirrel) or raw SQL, solely for these complex queries.
That’s the price to pay for type safety: we gain in rigor on 95% of the project, but we accept taking back manual control on the remaining 5%.
Miscellaneous subtleties
- As you may have noticed, NULL fields in SQL are represented with
sql.NullXxxin Go: this lets you handleNULLvalues without runtime errors (type-safe). - The
INSERT ... RETURNINGqueries are used to obtain the ID of a new record directly: sqlc translates them intoQueryRowContext(instead of a simpleExecContext) and usesScanto retrieve the returned value.
Note also that sqlc does not only generate code using the standard database/sql library but also supports pgx/v4 and pgx/v5.
Bonus: Mocking
I’d like to mention another advantage that stood out for me. Generating your code via sqlc greatly simplifies the mock, and for a good reason: we’re the ones who wrote the SQL script, so we know exactly what to expect.
This may seem trivial, but remember that if, via an ORM, we have no control over the SQL code that is actually generated behind the scenes, it can make mocks particularly tedious to write.
I want to mock the SELECT query generated behind my Get, what should I expect as a result? What is the exact query I need to intercept?
Let’s take GORM as an example:
|
|
It works, that’s cool. But I had to understand a little about how GORM works to know that it’s specifically this query that should be expected if I want to mock my Get function.
Does my ORM generate keywords in lowercase or uppercase? Does it use quotes or double-quotes? Does it systematically generate the table name before the associated column? Etc…
To answer these questions, you’ll need to read the documentation carefully, or even go straight to the ORM source code. You can also use the error messages of the SQL mock library you’re using, but you have to admit that this requires a bit of tinkering.
And that goes for every SQL query involved in your mocks.
When switching to sqlc, the mock will look like this:
|
|
In other words, exactly the query I wrote myself (or almost, see the SELECT * example, but the generated query is directly accessible).
When it comes to mocking up a whole battery of SQL queries for our unit tests, I’ve discovered how much more convenient it is to just have a simple copy-and-paste of my queries to do.
In my opinion, a solution like sqlc adds real value to the use of SQL mock libraries.
Conclusion
I think I’ve pretty much covered what I wanted to talk about.
I hope I’ve been able to convey why I became interested in this approach, which is a little different from what many of us commonly use.
In conclusion, ORMs like GORM offer a robust abstraction, facilitate migrations, and provide an intuitive CRUD interface. However, they require some learning investment (albeit minimal) and can introduce performance overhead, especially with large databases and complex operations.
On the other hand, raw SQL offers greater control over queries and can be more efficient for large databases, but it requires strong SQL expertise, involves a longer implementation process in Go code, and quickly becomes complex to manage as soon as you need queries with highly dynamic parameters.
So, I would say: if simplicity and rapid development are the priority, an ORM like GORM remains an excellent option. If optimization, precise control over queries, and type safety are essential, then I would recommend the sqlc approach, while keeping raw SQL in reserve for the most complex cases.
The point isn’t to say that one approach is better than the other.
I love ORMs and continue to use them in many of my projects, but I wanted to introduce you to this concept, which has been one of my favorites this year.
Finally, sqlc is increasingly proving to be a future-proof tool: while initially focused on the Go ecosystem, it is now expanding its horizons with official support (currently in beta) for languages like Python, Kotlin, or TypeScript, and many others via a plugin system.
Useful links
sqlc
- https://sqlc.dev/
- https://play.sqlc.dev/
- https://docs.sqlc.dev/en/stable/index.html
- https://github.com/sqlc-dev/sqlc
GORM
Comparison / Benchmark
- https://blog.jetbrains.com/go/2023/04/27/comparing-db-packages/
- https://medium.com/hyperskill/using-gorm-versus-plain-sql-to-interact-with-databases-in-go-39728974edc8
- https://www.codementor.io/@patriciotula/building-a-todos-app-in-go-comparing-database-sql-and-gorm-2n921bkfyk
My proof-of-concept
Many thanks to Gab who introduced me to this technology and got me interested!